विषय-सूचि
प्रोसेस और उनके प्रकार
ऑपरेटिंग सिस्टम में कोई प्रोसेस दो तरह का हो सकता है:
- इंडिपेंडेंट प्रोसेस
- को-ऑपरेटिंग प्रोसेस
इंडिपेंडेंट प्रोसेस वो प्रोसेस होते हैं जिनपर दूसरे प्रोसेस के एक्सीक्यूट होने का कोई असर नहीं होता जबकि को-ऑपरेटिंग प्रोसेस पर दूसरे एक्सीक्यूट हो रहे प्रोसेस का प्रभाव पड़ता है।
यद्दपि ऐसा कोई सोंच सकता है कि वो प्रोसेस जो स्वतंत्र रूप से कार्य कर रहे हैं वो ज्यादा एफिशिएंसी देते होंगे लेकिन असल में देखा जाये तो को-ऑपरेटिव व्यवहार को ही कम्प्यूटेशनल गति, सुविधा और modularity बढाने के लिए इस्तेमाल किया जाता रहा है।
इंटर-प्रोसेस कम्युनिकेशन (interprocess communication in os in hindi)
इंटर प्रोसेस कम्युनिकेशन एक ऐसा मैकेनिज्म है मैकेनिज्म है जो प्रोसेस को एक-दूसरे से संवाद करने की अनुमति देता है और उनके एक्शन को सिंक्रोनाइज करता है।
इन प्रोसेस के बीच का संचार को उनके बीच को-ऑपरेशन के व्यवहार की तरह देखा जा सकता है। प्रोसेस एक दूसरे से कम्यूनिकेट करने के लिए ये दो रास्ते अख्तियार करते हैं:
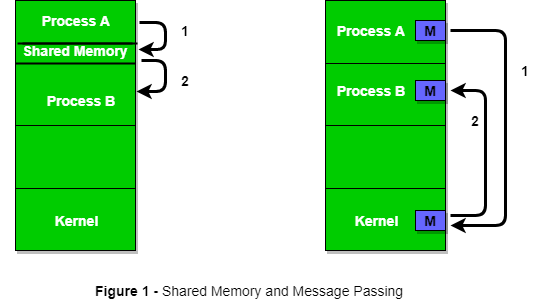
- शेयर्ड मेमोरी
- मैसेज पासिंग
नीचे चित्र में आप देख सकते हैं कि प्रोसेस के बीच शेयर्ड मेमोरी और मैसेज पासिंग के द्वारा कैसे कम्युनिकेशन होता है।
कोई ऑपरेटिंग सिस्टम दोनों ही चीजें यानी प्रोसेस और कम्युनिकेशन को इमप्लेमेंट कर सकता है। पहले हम कम्युनिकेशन के शेयर्ड मेमोरी मेथड की चर्चा करेंगे और फिर मैसेज पासिंग की। दो प्रोसेस के बीच शेयर्ड मेमोरी द्वारा कम्युनिकेशन के लिए प्रोसेस को कुछ वेरिएबल शेयर करने की जरूरत होती है और ये पूरी तरह इस पर निर्भर करता है कि प्रोग्रामर इसे कैसे इमप्लेमेंट करता है।
.शेयर्ड मेमोरी के साथ कम्युनिकेशन करने का तरीका कुछ इस तरह का होता है: मान लीजिये कि प्रोसेस 1 और प्रोसेस 2 साथ में ही एक्सीक्यूट हो रहे हैं और वो किसी अन्य प्रोसेस से कुछ संसाधन साझा करते हैं या फिर कोई सूचना का प्रयोग कर रहे हैं। अब प्रोसेस 1 कुछ ख़ास कम्प्यूटेशन और संसाधनों के बारे में में सूचनाएँ इकठ्ठा करेगा जो प्रयोग हो रहे हैं और उसे एक रिकॉर्ड की तरह शेयर्ड मेमोरी में रहेगा।
अब अगर प्रोसेसर 2 को उस शेयर्ड सूचना को एक्सेस करने की जरूरत होगी तो ये शेयर्ड मेमोरी में जो रिकॉर्ड हैं उन्हें चेक करेगा और प्रोसेसर 1 द्वारा बनाई गयी सूचनाओं को नोट करेगा और उसी हिसाब से कार्य करेगा।
प्रोसेस शेयर्ड मेमोरी को किसी और प्रोसेस से सूचना निकाल कर पढने के लिए भी प्रयोग कर सकते हैं और किसी दूसरे प्रोसेस को कोई सूचना देने के लिए भी इसका उपयोग किया जा सकता है। अब आइये शेयर्ड मेमोरी द्वारा कम्युनिकेशन के एक उदाहरण द्वारा समझते हैं कि ये कार्य कैसे करता है।
 प्रोडूसर और consumer प्रॉब्लम
प्रोडूसर और consumer प्रॉब्लम
यहाँ दो तरह के प्रोसेस हैं- प्रोडूसर और consumer. प्रोदुसस किसी आइटम का निर्माण करता है और consumer उस आइटम का प्रयोग करता है। ये दोनों ही प्रोसेस एक कॉमन मेमोरी या स्पेस लोकेशन को साझा करते हैं जिन्हें बफर कहा जाता है। यहाँ प्रोडूसर द्वारा प्रोडूस किया गया आइटम स्टोर किया हुआ रहता है और consumer जरूरत के अनुसार आइटम को यहीं से लाकर consumeकांसुमे करता है।
इस प्रॉब्लम के दो वर्जन हैं: पहले को अनबाउंड बफर प्रॉब्लम कहते हैं जिसमे प्रोडूसर आइटम को प्रोडूस करता रहता है और बफर के अंदर साइज़ का कोई लिमिट नहीं होता।
दूसरे वाले को bounded बफर प्रॉब्लम कहते हैं जिसमे प्रोडूसर एक निश्चित मात्रा में ही आइटम को प्रोडूस कर सकता है और उसके बाद ये consumer का इन्तजार करता है कि वो आइटम को consume करे। अब हम bounded बफर प्रॉब्लम की चर्चा करेंगे। पहले प्रोडूसर और consumer दोनों ही एक कॉमन मेमोरी को शेयर करेगा जिसके बाद प्रोडूसर आइटम को प्रोडूस करना शुरू कर देगा।
अगर कुल प्रोडूस किया हुआ आइटम बफर के आकार के बराबर हो जाएगा तब प्रोडूसर इसके consume होने का इन्तजार करेगा। ऐसे ही, consumer पहले आइटम की उपलब्धता के बारे में जांच करेगा और अगर आइटम उपलब्ध नहीं है तो consumer इन्तजार करेगा कि प्रोडूसर इसे प्रोडूस करे। अगर आइटम उपलब्ध है तो consumer इसे consume करेगा।
मैसेज पासिंग मेथड
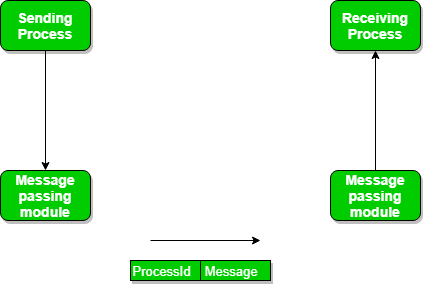
अब हम प्रोसेसर क्र बीच मैसेज पासिंग द्वारा होने वाले कम्युनिकेशन की बात करेंगे। इस मेथड में प्रोसेस एक-दूसरे से बिना किसी तरह के शेयर्ड मेमोरी का प्रयोग किये कम्यूनिकेट करेंगे।
अगर दो प्रोसेस P1 और P2 एक-दूसरे से कम्यूनिकेट करना चाहते हैं तो उनके बीच प्रक्रिया ऐसे होगी:
- सबसे पहले तो एक कम्युनिकेशन लिंक को स्थापित किया जाएगा। अगर लिंक पहले से ही मौजूद है तो इसे फिर से स्थापित करने की कोई जरूरत नहीं है।
- बेसिक प्रिमिटिव का प्रयोग कर के कम्युनिकेशन शुरू किया जाएगा।
हमारे पास ये दो प्रिमिटिव होने चाहिए-
– send(मैसेज, डेस्टिनेशन) or send(मैसेज)
– receive(मैसेज, होस्ट) or receive(मैसेज)
मैसेज का साइज़ निश्चित आकार का हो सकता है या फिर वेरिएबल भी हो सकता है।
अगर ये निश्चित आकार का है तो ये ऑपरेटिंग सिस्टम डिज़ाइनर के लिए आसान है लेकिन प्रोग्रामर के लिए मुश्किल होता है और अगर ये वेरिएबल आकार का है तो प्रोग्रामर के लिए आसान है लेकिन ऑपरेटिंग सिस्टम डिज़ाइनर के लिए कठिन हो जाता है। एक स्टैण्डर्ड मैसेज के दो पार्ट हो सकते हैं- हेडर और बॉडी।
हेडर का प्रयोग मैसेज टाइप, डेस्टिनेशन ID, सोर्स ID, मैसेज लेंथ और कण्ट्रोल सूचना को स्टोर करने के लिए किया जाता है। जबकि कण्ट्रोल सूचना में ऐसी चीजें रहती है जैसे कि जब चीजें बफर स्पेस से ज्यादा हो जाये तो क्या करना है, क्रम संख्या, प्रायोरिटी इत्यादि। सामान्यतः मैसेज को FIFO स्टाइल में भेजा जाता है।
कम्युनिकेशन लिंक द्वारा मैसेज पासिंग
डायरेक्ट और इनडायरेक्ट कम्युनिकेशन लिंक
अब हम हम कम्युनिकेशन लिंक को इप्लेमेंट करने के मेथड पर चर्चा आरम्भ करेंगे।
- लिंक को स्थापित कैसे किया जाता है?
- क्या एक लिंक को दो से ज्यादा प्रोसेसर के साथ जोड़ा जा सकता है?
- कम्युनिकेशन प्रोसेस के प्रत्येक पेअर के बीच कितने लिंक हो सकते हैं?
- लिंक की क्षमता क्या होती है? लिंक द्वारा रखे जाने वाले मैसेज का आकार निश्चित होता है या फिर वेरिएबल होता है?
- कोई लिंक यूनी-डायरेक्शनल होता है या बाई-डायरेक्शनल?
एक लिंक के पास कुछ कैपेसिटी होती है जो ये निर्णय लेता है कि अस्थाई तौर पर कितने मैसेज इसके अंदर रह पाएंगे। इसके लिए हर लिंक के साथ एक क्यू जुड़ा होता है जो या तो 0 कैपेसिटी का होता है या फिर bounded कैपेसिटी का।
जीरो कैपेसिटी में सेंडर तब तक इन्तजार करता है जब तक रिसीवर उसे ये सूचना न दे दे कि उसने मैसेज रिसीव कर लिया है। वहीं नॉन-जीरो कैपेसिटी वाले केस में सेंड ऑपरेशन के होने के बाद प्रोसेस को ये पता नहीं होता कि मैसेज रिसीवर तक पहुचा भी है या नहीं। इसके लिए रिसीवर को सेंडर से अलग से कम्यूनिकेट करना चाहिए। लिंक का इम्प्लीमेंटेशन स्थिति पर निर्भर करता है, ये या तो डायरेक्ट कम्युनिकेशन लिंक हो सकता है या फिर इनडायरेक्ट कम्युनिकेशन लिंक भी हो सकता है।
डायरेक्ट कम्युनिकेशन लिंक को तब इमप्लेमेंट किया जाता है जब प्रोसेस किसी ख़ास प्रोसेस आइडेंटिफायर का इस्तेमाल कर के कम्युनिकेशन करते हैं लेकिन समय से पहले सेंडर को पहचान पाना मुश्किल होता है। उदाहरण के तौर पर प्रिंट सर्वर। इनडायरेक्ट कम्युनिकेशन लिंक को एक श्रेड मेलबॉक्स द्वारा किया जाता है जिसे पोर्ट भी कहते हैं,इसमें मैसेज के क्यू होते हैं। सेंडर मैसेज को मेलबॉक्स में रखते हैं और फिर रिसीवर उसे उठाता है।
मैसेज के exchanging द्वारा मैसेज पासिंग
सिंक्रोनस और असिंक्रोनस मैसेज पासिंग
ऐसा प्रोसेस जिसे ब्लोक किया गया हो वो किसी इवेंट के लिए इन्तजार कर रहा होता है, जैसे कि किसी I/Oओ पेरातिओं के लिए संसाधन का उपलब्ध होना। नेटवर्क या डिस्ट्रिब्यूटेड सिस्टम में समान कंप्यूटर में रह रहे प्रोसेस या दो अलग-अलग कंप्यूटर के प्रोसेस के बीच भी IPCइप्क सम्भव है। दोनों ही स्थितियों में प्रोसेस ब्लोक हो भी सकता है या नहीं भी। वहीं किसी मैसेज को भेजना या मैसेज को प्राप्त करने की चेष्टा करना ताकि मैसेज जो पास हो रहा है वो ब्लोकिंग भी हो सकता है या नॉन-ब्लोकिंग भी। व्लोच्किंग को सिंक्रोनस मन जाता है और ब्लॉकिंग सेंड का रथ हुआ सेंडर तब तक ब्लाक रहेगा जब तक रिसीवर द्वारा मैसेज प्राप्त न कर लिया जाए।
इसी तरह ब्लॉकिंग रिसीव के पास रिसीवर ब्लाक रहता है जबतक कोई मैसेज उपलब्ध न हो।नॉन-ब्लॉकिंग को असिंक्रोनस मन जाता है और नॉन-ब्लॉकिंग सेंड के पास सेंडर मैसेज भेजता है और ऐसा होता रहता है। ऐसे ही नॉन-ब्लॉकिंग रिसीव का अर्थ हुआ रिसीवर या तो कोई सही मैसेज प्राप्त करे या फिर नल। सावधानी से विश्लेषण करने के बाद हम इस नतीजे पर पहुँच सकते हैं कि सेंडर के लिए मैसेज पासिंग के बाद नॉन-ब्लॉकिंग होना ज्यादा सहज होता है क्योंकि मैसेज को विभिन्न प्रोसेस के पास भेजने की जरूरत पड़ सकती है। लेकिन अगर सेंड फ़ैल हो गया तो सेंडर रिसीवर से acknowledgement की अपेक्षा रखता है।
ठीक इसी तरह से एक रिसीवर के लिए रिसीव को एक सूचना कि तरह इशू करने के बाद ब्लॉकिंग होना ज्यादा सहज होता है। वहां रिसीव किया हुआ मैसेज बाद में execution के लिए प्रयोग किया जा सकता है लेकिन उसी समय पर अगर मैसेज सेंड बार-बार फ़ैल होता रहे तो रिसीवर को हमेशा के लिए इन्तजार करते रह जाना पड़ सकता है।
इसीलिए हम मैसेज पासिंग की दूसरी सम्भावना पर विचार करते हैं। इसके लिए ये तीन कॉम्बिनेशन हैं जिनका ज्यादा प्रयोग किया जाता है:
- ब्लॉकिंग सेंड और ब्लॉकिंग रिसीव
- नॉन-ब्लॉकिंग सेंड और नॉन-ब्लॉकिंग रिसीव
- नॉन ब्लॉकिंग सेंड और ब्लॉकिंग रिसीव (सबसे ज्यादा प्रयोग होने वाला)
डायरेक्ट मैसेज पासिंग
इसमें जो प्रोसेस कम्यूनिकेट करना चाहता है उसे अलग से प्राप्तकर्ता और कम्युनिकेशन के सेंडर का नाम बताना होता है।
उदाहरण के लिए, send(p1, message) का अर्थ हुआ कि P1 को मैसेज भेजा जाये।
और ठीक उसी तरह, receive(p2, message) कि मैसेज को P2 से भेजा जाए।
कम्युनिकेशन की इस प्रक्रिया में कम्युनिकेशन लिंक अपने-आप स्थापित हो जाता है जो कि यूनी-डायरेक्शनल और बाई-डायरेक्शनल दोनों ही हो सकता है। सेंडर और रिसीवर के एक पेअर के बीच एक लिंक का प्रयोग किया जा सकता है और रिसीवर के पास एक से ज्यादा लिंक नहीं होने चाहिए। सेंडर और रिसीवर के बीच सिमिट्री या असिमिट्री भी इमप्लेमेंट की जा सकती है।
या तो दोनों ही प्रोसेस सेंड और रिसीव करने के लिए एक-दूसरे का नाम लेंगे या फिर केवल सेंडर ही मैसेज सेंड करने के लिए रिसीवर का नाम लेगा और रिसीवर द्वारा मैसेज प्राप्त करने के लिए इंदर का नाम लेना जरूरी नहीं होगा। इस कम्युनिकेशन की प्रक्रिया के साथ समस्या ये हैं कि अगर एक प्रोसेस का भी नाम बदल गया तो ये काम नहीं करेगा।
इनडायरेक्ट मैसेज पासिंग
इनडायरेक्ट मैसेज पासिंग में प्रोसेस मैसेज को सेंड और रिसीव करने के लिए मेलबॉक्स का प्रयोग करते हैं जिन्हें हम पोर्ट्स भी कहते हैं। हर मेलबॉक्स की एक ख़ास ID होती है और प्रोसेस तभी कम्यूनिकेट कर सकते हैं जब वो मेलबॉक्स को साझा कर रहे हों। जब प्रोसेस एक कॉमन मेलबॉक्स को शेयर कर रहे हों तभी लिंक स्थापित होता है और बहुतों प्रोसेस के लिए एक सिंगल लिंक को जोड़ा जा सकता है। प
रोसेस के हर एक पेअर बहुत आरे कम्युनिकेशन लिंक हरे कर सकते हैं और ये लिंक यूनी-डायरेक्शनल या बाई-डायरेक्शनल हो सकता है। मान लीजिये कि दो प्रोसेस इनडायरेक्ट मैसेज पासिंग के जरिये आपस में कम्यूनिकेट करना चाह रहे हों तो उसके लिए ये ऑपरेशन की जरुरत पड़ेगी: एक मेल बॉक्स को बनाना, इस मेलबॉक्स के प्रयोग से मैसेज को सेंड और रिसीव करना, मेलबॉक्स को डिस्ट्रॉय करना यानी हटा देना।
टैण्डर्ड प्रिमिटिव होते हैं- send(A, message) जिसका मतलब हुआ मैसेज को मेलबॉक्स A को भेजा जाये और ऐसे ही रीसिव मैसेज का प्रिमिटिव received (A, message) भी कार्य करता है। लेकिन इस मेलबॉक्स वाले सिस्टम में एक समस्या भी है। ,मान लीजिये दो से ज्यादा प्रोसेस समान मेलबॉक्स को ही साझा कर रहे हैं और प्रोसेस P1 मेलबॉक्स में कोई मैसेज भेजता है तो कौन सा प्रोसेस रिसीवर होगा? इसका हल या दो एक मेलबॉक्स को सिर्फ दो ही प्रोसेसर को रखने का नियम बना कर निकाला जा सकता है या फिर ये नियम बनाया जा कता है कि एक समय में एक ही प्रोसेसर को एक्सीक्यूट होने की अनुमति मिलेगी। इसमें किसी प्रोसेस को रैंडम तरीके से चुना जाएगा और रिसीवर को सेंडर के बारे में बता दिया जाएगा।
एक मेलबॉक्स को किसी सिंगल सेंडर या रिसीवर को प्राइवेट रूप से भी असाइन किया जा सकता है और एक से ज्यादा सेंडर और रिसीवर के पेअर के बीच भी शेयर किया जा सकता है। उदाहरण के तौर पर पोर्ट ऐसे मेलबॉक्स का इम्प्लीमेंटेशन है जिसके पास कई सेंडर और रिसीवर हो सकते हैं। इसे क्लाइंट सर्वर एप्लीकेशन में प्रयोग किया जाता है जहां सर्वर रिसीवर होता है। पोर्ट को रिसीविंग प्रोसेस द्वारा रखा जाता है औरे रिसीवर प्रोसेस के निवेदन पर ऑपरेटिंग सिस्टम द्वारा बनाया जाता है। इसे समान रिसीवर प्रोसेस के आग्रह पर नष्ट भी किया जा सकता है या फिर जब रिसीवर खुद को टर्मिनेट कर ले।
इस नियम को तय कर के कि एक समय में एक ही प्रोसेस को एक्सीक्यूट होने की अनुमति मिलेगी, काफी आसानी हो जाती है और इसे म्यूच्यूअल एक्सक्लूशन के कांसेप्ट द्वारा किया जाता है। म्यूटेक्स मेलबॉक्स को बनाया जाता है जिसे n संख्या में प्रोसेस द्वारा शेयर किया जाता है।
सेंडर नॉन-ब्लॉकिंग होता है और मैसेज को सेंड करता है। वो पहला प्रोसेस जो रिसीव को एक्सीक्यूट करता है वो क्रिटिकल सेक्शन में जाता है जबकि बांकी सारे प्रोसेस ब्लॉकिंग कर रहे होंगे और इन्तजार करेंगे।
इस लेख से सम्बंधित यदि आपका कोई भी सवाल या सुझाव है, तो आप उसे नीचे कमेंट में लिख सकते हैं।